library(data.table)
library(flextable)
library(ggplot2)
library(reticulate)
library(stm)
library(tidytext)
subreddit_submissions <-
fread("data/subreddit_submissions.csv")AI agents are everywhere right now. Nearly every workflow is being rebranded as “AI.” Psychometric measures supposedly “handled by an AI agent,” forms replaced with a voice model. On the surface, impressive. But let’s be honest: a percentile score doesn’t need an agent, and a basic form can handle initial screening. I’m not convinced.
Tools like Lovable, N8N, and others have also flooded the space with a wave of “vibe-coded” apps. Many even leak their own API keys in network calls. The result is a stream of identical-looking products, some claiming to be health or finance tools while overlooking basic security.
This post looks at how these AI services have fed into the constant push to make money fast. To do that, we’ll dive into the r/AI-Agents subreddit. The goal is simple: understand how this community posts and what they’re actually building.
Subreddit Posts
Using PRAW, I pulled 978 submissions from the subreddit. All data was collected on 12 November 2025. It’s still only a sample, so treat it as indicative rather than definitive.
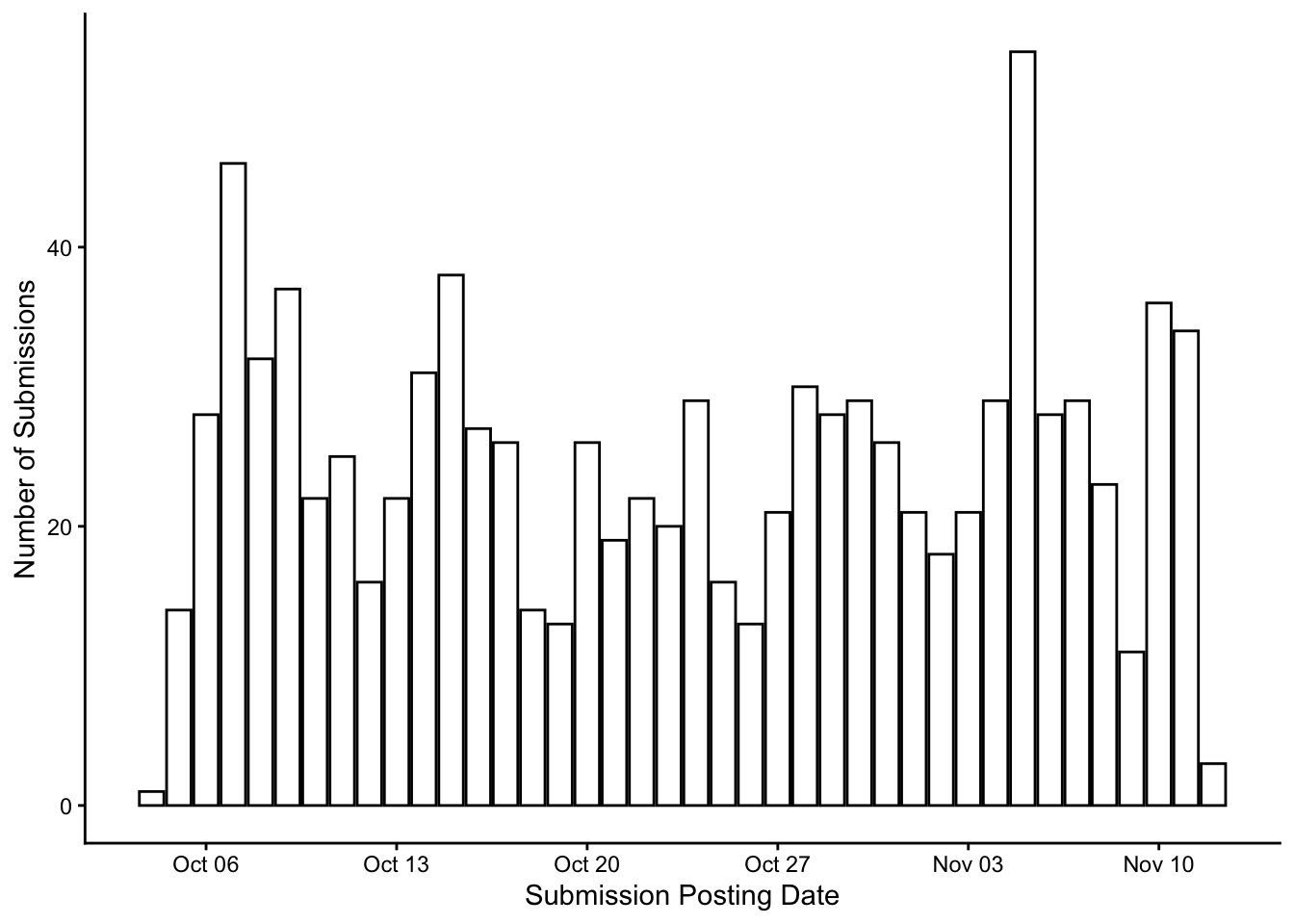
The posting pattern by day is steady across the month (Figure 1) . Nothing substantial, but enough activity to show the subreddit has a consistent audience, and that people are genuinely interested in the idea of building AI agents.
subreddit_submissions[, created_utc := as.POSIXct(created_utc)]
subreddit_submissions[, .N, by = .(posted_date = as.Date(created_utc))] |>
ggplot(aes(x = posted_date, y = N)) +
geom_col(
colour = "black",
fill = "white"
) +
theme_classic() +
labs(
x = "Submission Posting Date",
y = "Number of Submissions"
)
For the analysis of these posts, we’ll triangulate across three approaches:
Embeddings
Topic modelling
Large language models
Each helps explore the types of content being posted and whether the themes shift over time.
Embeddings
The submission titles are encoded into embeddings, which are then averaged by week. These weekly averages are compared using cosine similarity to check for semantic shifts.
import pandas as pd
from sentence_transformers import SentenceTransformer
from sklearn.metrics.pairwise import cosine_distances
model = SentenceTransformer("all-mpnet-base-v2")
subreddit_submissions = r.subreddit_submissions
subreddit_submissions["embeddings"] = subreddit_submissions["title"].apply(model.encode)
subreddit_submissions["week_of_year"] = subreddit_submissions["created_utc"].dt.strftime("%W")
week_embeddings = subreddit_submissions.groupby("week_of_year")["embeddings"].mean()
cosine_matrix = model.similarity(week_embeddings, week_embeddings)
cosine_matrix = pd.DataFrame(cosine_matrix, index=week_embeddings.index, columns=week_embeddings.index)Inspecting the cosine similarity matrix, Week 39 stands out: it’s less similar to the other six weeks, which cluster tightly together.
cosine_matrix <-
py$cosine_matrix |>
as.matrix()
cosine_matrix[upper.tri(cosine_matrix)] <- NA
cosine_matrix <- round(cosine_matrix, 3)
cosine_matrix 39 40 41 42 43 44 45
39 1.000 NA NA NA NA NA NA
40 0.915 1.000 NA NA NA NA NA
41 0.916 0.987 1.000 NA NA NA NA
42 0.912 0.988 0.984 1.000 NA NA NA
43 0.896 0.984 0.981 0.982 1.000 NA NA
44 0.912 0.986 0.983 0.983 0.982 1.000 NA
45 0.888 0.967 0.968 0.967 0.969 0.971 1A simple explanation shows up in the weekly counts. Week 39 contains only 15 posts, compared with 206 in Week 40. With such a small sample, the averaged embedding for Week 39 is more sensitive to topic variation and noise.
subreddit_submissions <-
py$subreddit_submissions |>
as.data.table()
subreddit_submissions[, .N, by = .("Created Week" = week_of_year)] |>
as_flextable()Created Week | N |
|---|---|
character | integer |
45 | 73 |
44 | 195 |
43 | 173 |
42 | 145 |
41 | 171 |
40 | 206 |
39 | 15 |
n: 7 | |
Overall, the cosine similarities suggest minimal semantic drift across weeks, aside from Week 39, which is likely an artefact of low volume. With short titles and uneven posting counts, embeddings give a high-level signal rather than detailed semantic structure.
Topic Modelling
For topic modelling, the submission titles are pre-processed and tokenised, then analysed using the structural topic modelling (STM) package.
The workflow is straightforward:
Multiple models are fitted with different numbers of topics. Each model is evaluated using exclusivity and semantic coherence.
The topic count with the best balance of these metrics is selected as the preferred solution.
STM is then re-run several times using this chosen topic number to account for variability in model initialisation.
From these runs, the model with the strongest exclusivity–coherence profile is retained for interpretation.
Results of this process showed a 3 topic solution to be preferential.
processed_text <-
textProcessor(
documents = subreddit_submissions$title
)
prepared_text <-
prepDocuments(
documents = processed_text$documents,
vocab = processed_text$vocab
)
search_k <-
searchK(
documents = prepared_text$documents,
vocab = prepared_text$vocab,
K = 2:7
)
multi_topics <-
selectModel(
documents = prepared_text$documents,
vocab = prepared_text$vocab,
K = 3,
runs = 100,
seed = 1410
)
selected_model <-
multi_topics$runout[[2]]An inspection of the top words for each topic provides insight into the model’s interpretation.
Topic 1 focuses on building “AI agents,” especially around design principles and open-source models.
Topic 2 is about projects and workflows, often linked to sales or productivity.
Topic 3 captures products people have built, what they need, and requests for testing or feedback.
labelTopics(selected_model)Topic 1 Top Words:
Highest Prob: agent, build, use, voic, make, best, free
FREX: sourc, sdk, open, get, model, best, design
Lift: ’re, action, almost, behind, design, easier, email
Score: agent, build, voic, use, best, new, make
Topic 2 Top Words:
Highest Prob: autom, look, tool, anyon, can, help, workflow
FREX: engin, sale, talk, train, project, workflow, far
Lift: engin, far, suggest, agentkit, aiml, appli, background
Score: autom, tool, workflow, anyon, like, learn, busi
Topic 3 Top Words:
Highest Prob: built, actual, need, work, code, just, platform
FREX: work, code, product, test, now, claud, differ
Lift: work, accident, add, agi, altern, amaz, author
Score: built, work, code, actual, product, need, just We extend the insight into these topics by sampling representative titles from each one.
Topic 1 focuses on seeking feedback, discussion, and advice on builds.
titles_retained <-
subreddit_submissions$title
titles_retained <-
titles_retained[-prepared_text$docs.removed]
model_titles <-
findThoughts(selected_model, titles_retained)
plotQuote(model_titles$docs[[1]])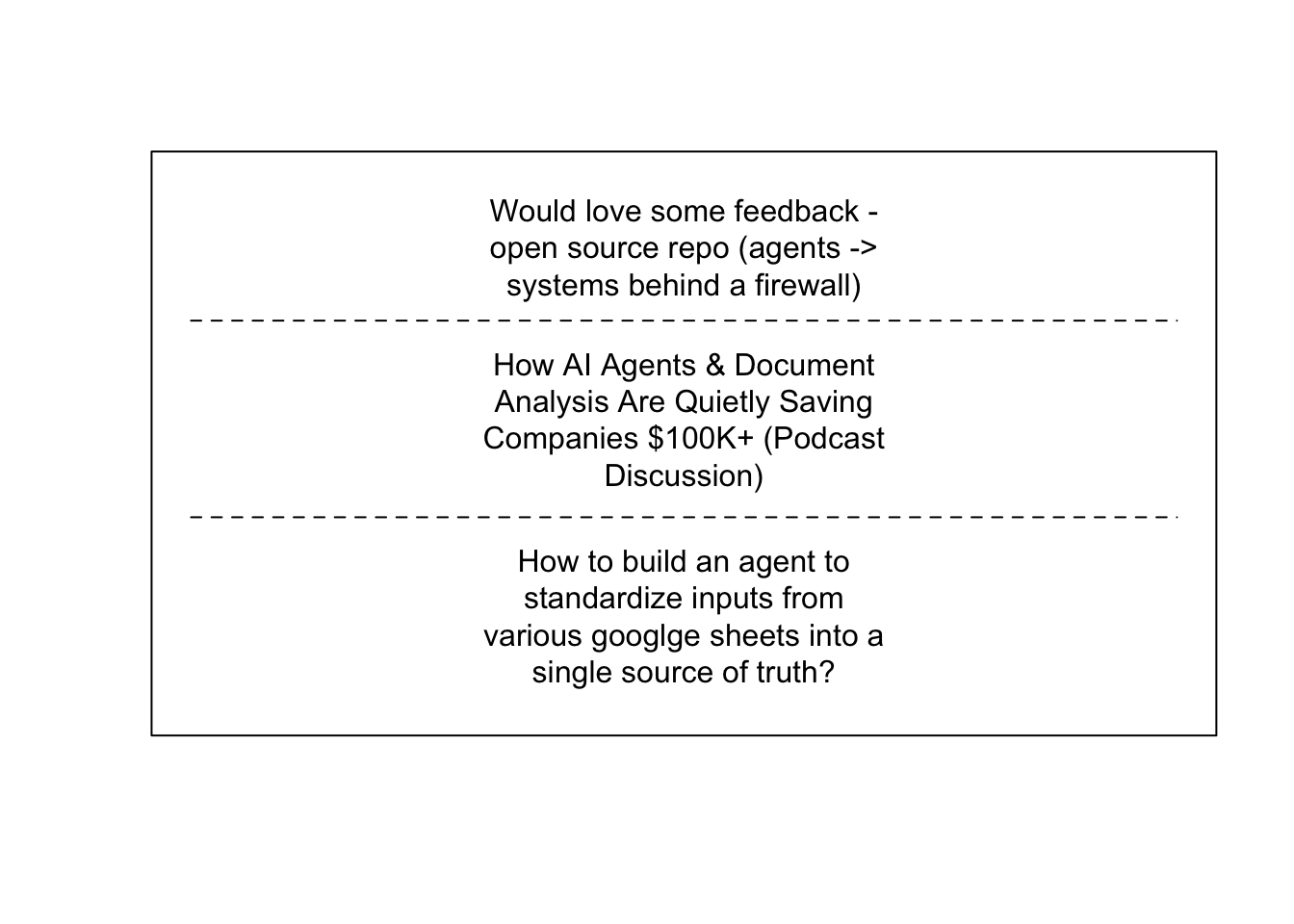
Topic 2 centres on selling workflows, promoting sales opportunities, and offering paid work.
plotQuote(model_titles$docs[[2]])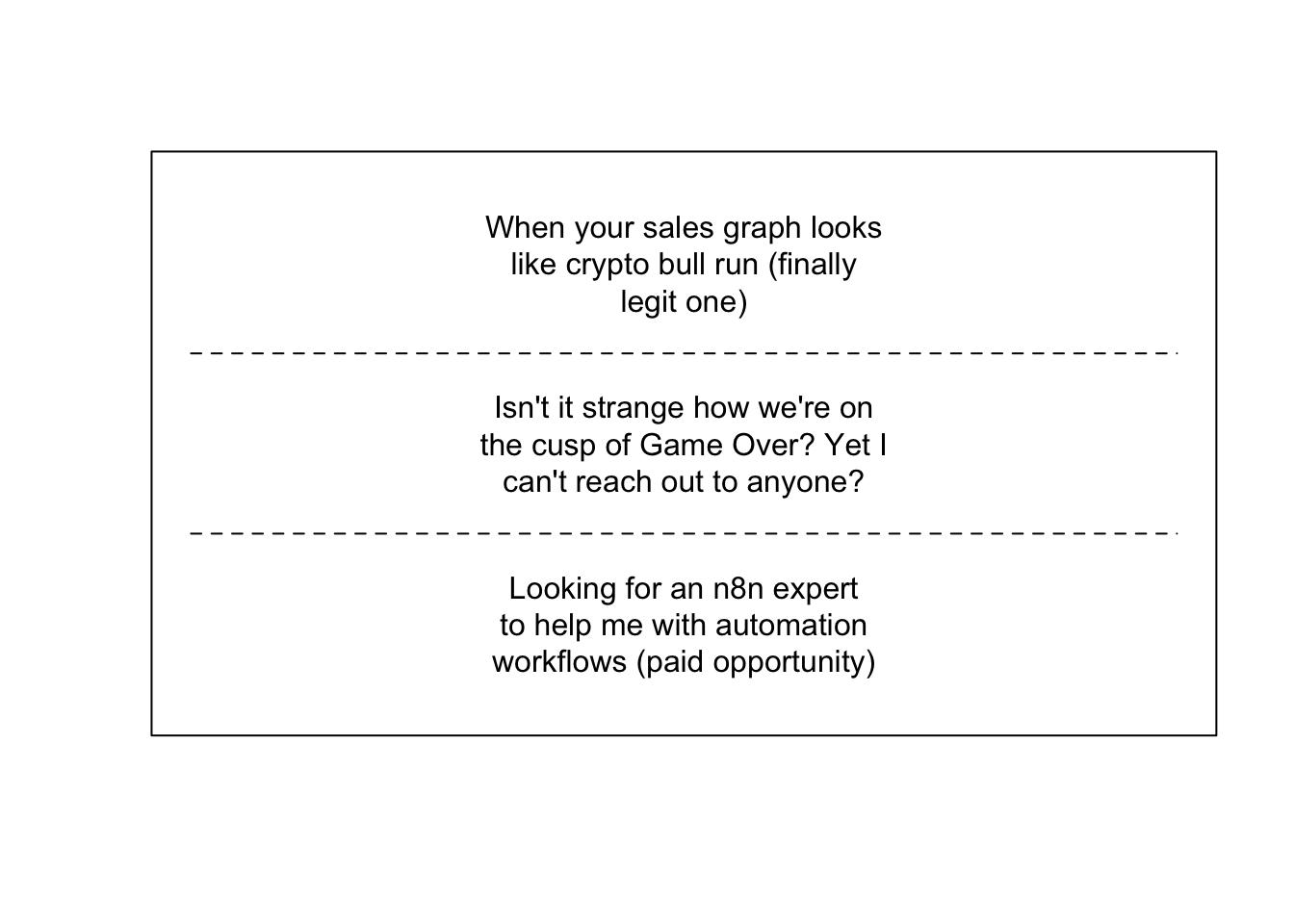
Topic 3 highlights people showcasing their builds and giving advice to others.
plotQuote(model_titles$docs[[3]])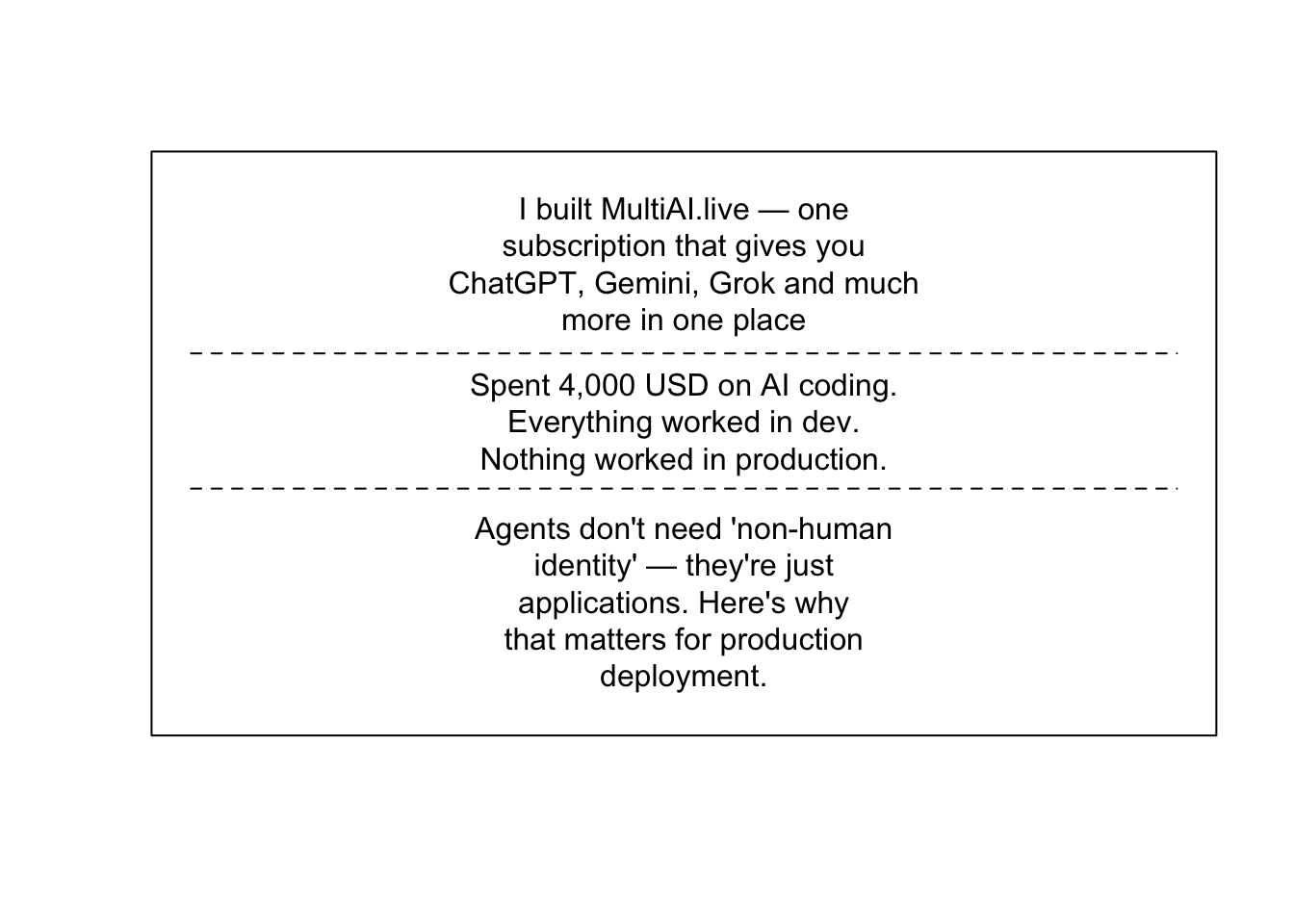
We assign each post to a topic using the maximum posterior topic proportion. Using these assignments, we examine topic presence by week. The pattern mirrors the embedding results: Week 39 shows very little Topic 3 activity and a heavier presence of Topic 2.
subreddit_submissions <-
subreddit_submissions[-prepared_text$docs.removed]
subreddit_submissions[, topic := apply(selected_model$theta, 1, which.max)]
prop.table(table(subreddit_submissions$week_of_year, subreddit_submissions$topic), margin = 1)
1 2 3
39 0.53333333 0.40000000 0.06666667
40 0.49756098 0.25365854 0.24878049
41 0.45882353 0.25882353 0.28235294
42 0.44366197 0.26056338 0.29577465
43 0.45562130 0.21893491 0.32544379
44 0.50785340 0.18848168 0.30366492
45 0.49315068 0.17808219 0.32876712Overall, the topic distribution is steady across most weeks, with Week 39 as the main outlier. Its heavier focus on Topic 2 and near-absence of Topic 3 supports the earlier embedding results: the week’s content is structurally different, likely due to the low number of posts. Beyond that, the subreddit shows consistent patterns in what people ask for, what they build, and what they try to sell.
Large Language Models
DeepSeek was prompted to extract topics and trends based on submission titles and dates.
Main Topics:
AI Agent Development – Building agents, frameworks, tools, and technical issues.
Business Automation – Workflows, sales, customer service, and basic automation.
Voice AI Agents – Voice platforms, use cases, and tooling.
Agent Evaluation & Reliability – Testing, failures, debugging, and deployment concerns.
Learning & Getting Started – Beginner questions and early entry into the space.
Given the short window, shifts are small. Early posts focus on learning; later posts move toward building agents and discussing frameworks. Voice AI appears more toward the end, while business automation stays steady throughout.
Taken together, the embeddings, topic modelling, and LLM summaries point to the same pattern: most posts revolve around building and selling agents, with only minor variation week to week. The subreddit is active, but the themes are narrow and largely driven by new tools entering the space.