from adaptivetesting.implementations import TestAssembler
from adaptivetesting.math.estimators import ExpectedAPosteriori, NormalPrior
from adaptivetesting.math.item_selection import maximum_information_criterion
from adaptivetesting.models import ItemPool
from adaptivetesting import ResultOutputFormat
from adaptivetesting.simulation import Simulation
from adaptivetesting import StoppingCriterion
from itertools import batched
from numpy import random
# Item Information -------
thresholds = [-4.783526927138332, -1.400211193241816, -4.149947201689546, -1.235480464625132, -2.996832101372756, -0.44984160506863713, -2.870116156282999, -0.5638859556494191, -2.3632523759239703, -0.9313621964097143, -2.198521647307286, -0.2344244984160504, -2.135163674762407, 0.1710665258711721, -2.147835269271383, 0.2977824709609296, -1.628299894403379, -0.14572333685322025, -1.8310454065469903, 0.43717001055966254, -1.6409714889123546, 0.5258711721224927, -1.7170010559662092, 0.6906019007391766, -0.8553326293558605, 0.8173178458289341, -0.8933474128827879, 1.1341077085533264, -1.12143611404435, 1.62829989440338, -0.5638859556494191, 1.5269271383315735, 0.43717001055966254, 2.0337909186906025, 0.3484688489968324, 2.2618796198521647, -0.08236536430834196, 3.034846884899684, 0.42449841605068706, 2.781414994720169, 0.6399155227032738, 2.7053854276663145, 1.0960929250264, 3.0475184794086587, 1.9831045406546997, 3.7191129883843725, 2.8447729672650475, 5.024287222808871]
thresholds = [[threshold[0], threshold[1]] for threshold in batched(thresholds, 2)]
item_pool = ItemPool.load_from_list(thresholds)Previous CAT posts have focused on dichotomous items, those scored 0 or 1. In reasoning assessment this reflects correctness; in attitudinal measurement it reflects a binary agree/disagree response. Polytomous items extend this to ordered response categories, most commonly Likert scales where respondents indicate their level of agreement or the importance of a statement across multiple points.
To run the simulation, we use the adaptivetesting Python package. Unlike catsim, which featured in earlier posts, adaptivetesting handles both dichotomous and polytomous items. Like catsim, adaptivetesting supports real data collection alongside simulation.
The item bank is drawn from the I-RODS (Inflammatory Rasch-built Overall Disability Scale), a 24-item patient-reported outcome measure for immune-mediated neuropathies Pelouto et al. For the CAT, we only need the item thresholds. Discrimination values are fixed to 1 across all items, which effectively reduces the Generalised Partial Credit Model to the simpler Partial Credit Model — we specify GPCM since that’s what the package expects, but the parameterisation is PCM in practice.
The model parameter isn’t passed through to generate_response_pattern during initialisation, meaning GPCM responses are never actually generated. We patch this using functools.partial.
from adaptivetesting.math import generate_response_pattern
from adaptivetesting.models.__adaptive_test import AdaptiveTest
from functools import partial
# Patch generate_response_pattern to always pass model="GPCM"
import adaptivetesting.models.__adaptive_test as _at_module
original_grp = _at_module.generate_response_pattern
_at_module.generate_response_pattern = partial(original_grp, model="GPCM")For the simulation, we draw 100 samples from a uniform distribution across the full ability range [-6, 6]. Sampling uniformly ensures coverage at the extremes, where item targeting tends to be weakest. The CAT is run with an incrementing length stopping criterion, starting at 10 items and increasing by one up to the maximum of 24. For each run, the SE (standard error) stopping criterion is set at 0.30.
# Simulated Sample --------
r = random.RandomState(626)
theta_samples = r.uniform(-6, 6, 100)
for n_items in range(10, len(thresholds) + 1):
adaptive_tests = [
TestAssembler(
item_pool=item_pool,
model_type="GPCM",
simulation_id=f"ods_scale_length_{n_items}",
participant_id=str(index),
ability_estimator=ExpectedAPosteriori,
estimator_args={
"prior": NormalPrior(0,1),
"optimization_interval": (-10,10),
"model": "GPCM"
},
item_selector=maximum_information_criterion,
true_ability_level=theta
)
for index, theta in enumerate(theta_samples)
]
for test in adaptive_tests:
simulation = Simulation(test, ResultOutputFormat.CSV)
simulation.simulate(
criterion=[StoppingCriterion.SE, StoppingCriterion.LENGTH],
value=[.30, n_items]
)
simulation.save_test_results()Results are stored as CSVs. We iterate over and concatenate them for analysis.
import pandas as pd
from pathlib import Path
from plotnine import *
import os
simulation_results = pd.DataFrame()
for results in os.walk("data"):
root, folder, files = results
if not folder:
for file in files:
result_file = Path(root) / Path(file)
results = pd.read_csv(result_file)
results["respondent_id"] = file.replace(".csv", "").strip()
results["test_length"] = results["test_id"].str.extract("([0-9]+)").astype(int)
simulation_results = pd.concat([results, simulation_results])In every run, the test ran to the length cap. The SE stopping criterion was never met, meaning no simulation terminated early on account of precision.
test_lengths = (
simulation_results
.groupby(["respondent_id", "test_length"])["test_length"]
.agg(count="count")
.reset_index()
)
early_termination_count = sum(test_lengths.apply(lambda x: 1 if x["test_length"] != x["count"] else 0, axis=1))
print(f"There were {early_termination_count} instances of the simulation terminating early on account of the standard error meeting the stopping criteria.")There were 0 instances of the simulation terminating early on account of the standard error meeting the stopping criteria.We explore uncertainty in the final ability estimates by plotting SE against true ability level, faceted by test length.
final_estimate = simulation_results.groupby(["test_length", "respondent_id"]).tail(1)
(
ggplot(final_estimate, aes("true_ability_level", "standard_error")) +
geom_jitter(alpha=.4) +
facet_wrap("~test_length") +
theme_538() +
labs(
x = "True Ability Level",
y = "Standard Error (SE)"
)
)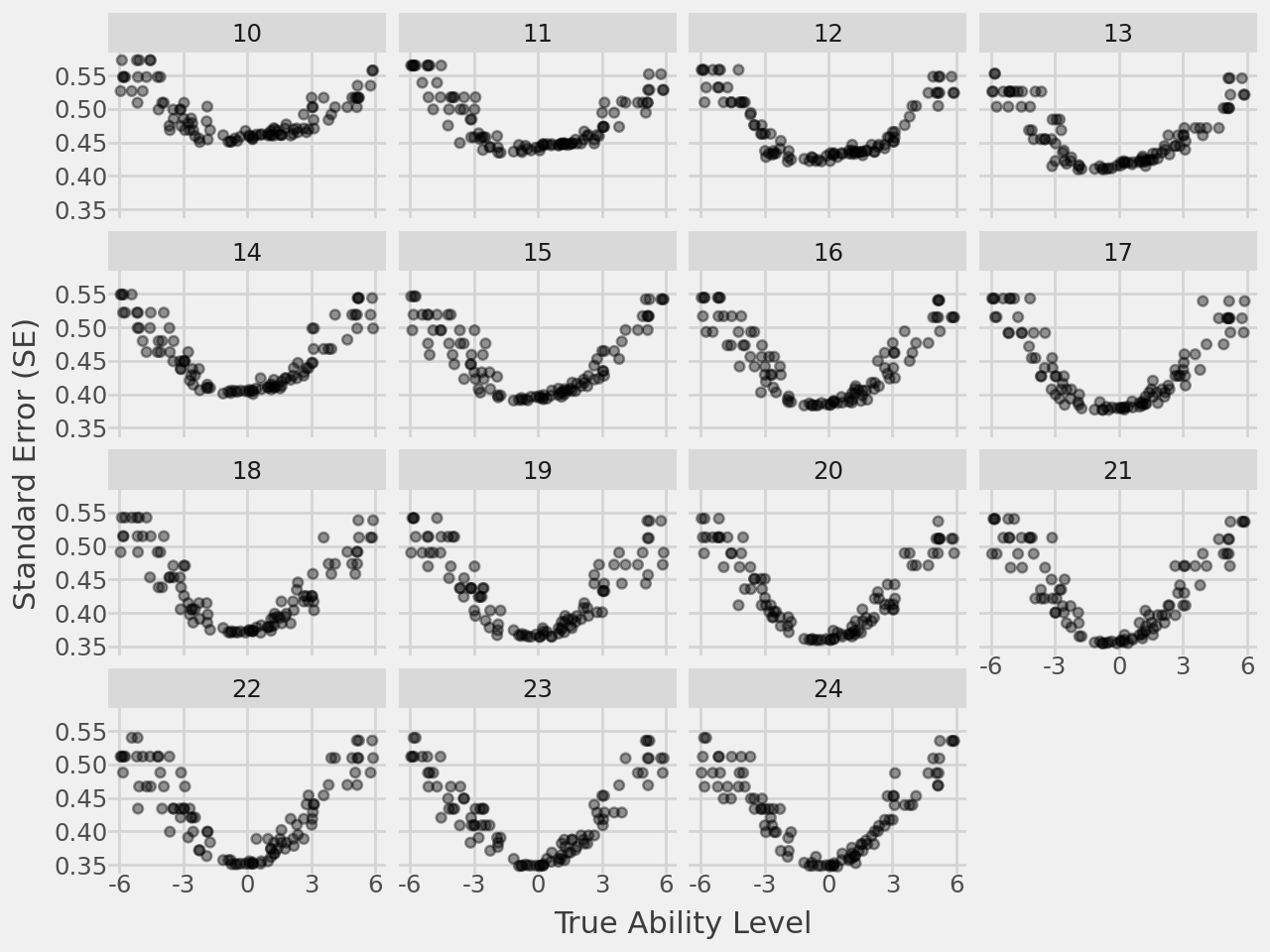
SE reduces with increasing test length, as expected. More items means more information per respondent. Diminishing returns set in around 17 items, with little meaningful reduction beyond that point.
The more interesting pattern is the persistent U-shape across all facets. SE is lowest for respondents in the middle of the ability range and elevated at both extremes, and this shape barely changes with test length. Additional items are doing most of their work in the centre; they’re contributing relatively little at the tails. Given that this scale is designed to capture limitations in daily activity and social participation, the difficulty range should ideally extend further into severe impairment. The ceiling effects noted by Pelouto et al. are visible here in measurement terms, the items simply don’t target that region well enough for the adaptive algorithm to reduce uncertainty there, regardless of how many items are administered.
The adaptivetesting package offers a straightforward route to polytomous CAT simulation, and the GPCM implementation works well once the model parameter bug is patched. The I-RODS item bank illustrates a common practical constraint, a pool developed for fixed-length administration doesn’t automatically translate to an effective adaptive one. The SE stopping criterion going unmet across all runs, and the persistent elevation at the ability extremes, both reflect a bank that wasn’t designed with adaptive targeting in mind.
As for the scale, whether that means augmenting the existing pool or building one from scratch is a question for another post.