library(data.table)
library(flextable)
library(ggplot2)
library(reticulate)Overview
Just finished watching You. Interesting end to the show... It got me thinking about how character profiles can be used to get AI (like GPT) to respond to psychometric questionnaires. I've done this before using It's Always Sunny in Philadelphia characters to explore conspiratorial beliefs. That approach, though, was limited to a single run per character.
In this post, I'm taking a similar approach but testing consistency: what happens when you run the same character prompt multiple times—do the psychometric scores stay the same?
Back to You. Narcissism is portrayed strikingly in the main character. Contrary to popular belief, narcissism isn't always loud and boastful. It exists on a continuum—from overt grandiosity at one end to more covert, subtle expressions at the other. For any further details, I recommend reading Psychopath Free.

Approach
To generate character profiles for the experiment, I began by prompting Claude to create three groups, each with five distinct fictional characters:
Five characters with strong narcissistic traits,
Five characters with mild narcissistic traits,
Five characters with no narcissistic traits.
For each character, Claude provided an accompanying profile. However, the initial output proved problematic—the descriptions of narcissism were often too blatant, risking bias if another AI were to complete a personality questionnaire based on these profiles. Overtly obvious traits might inadvertently signal the intended results rather than allow for genuine assessment.
To address this, I instructed Claude to refine and nuance each profile, specifically minimising explicit displays of narcissism where present. This iterative process aimed to create subtle, believable characters, reducing the risk of response bias in subsequent analysis.
For measuring narcissistic traits, I utilised two validated instruments:
The 16-Item Narcissistic Personality Inventory (NPI-16)
The Hypersensitive Narcissism Scale (HNS)
Prompts
Two distinct prompts were designed, tailored to the requirements of each narcissism scale:
For the NPI-16: The prompt presents each pair of contrasting statements, asking the respondent (in this case, the AI role-playing as a character) to select the statement that best describes them. Each response is scored as either 0 or 1, and the overall score is calculated as the average of these values.
For the HNS: The prompt instead lists the scale’s statements and requests a response on a 5-point Likert scale, ranging from 1 (“Very Uncharacteristic”) to 5 (“Very Characteristic”).
In both cases, a placeholder is included in the prompt where the relevant character profile is inserted, ensuring that the AI answers from the perspective of that specific character.
Finally, to facilitate quantitative analysis, the prompts instruct the AI to provide output in a structured JSON format.
### Instruction
I am going to provide a character profile. Based on the profile, I want you to select amongst a series of 16 item pairs the item that you identify with the most. If you do not identify with either of them, choose the one that is least objectionable or remote.
### Character Profile
Character Profile: {{character_profile}}
### Questionnaire Items
Item 1: When people compliment me I sometimes get embarrassed **vs** I know that I am good because everybody keeps telling me so
Item 2: I prefer to blend in with the crowd **vs** I like to be the center of attention
Item 3: I am no better or worse than most people **vs** I think I am a special person
Item 4: I don’t mind following orders **vs** I like having authority over people
Item 5: I don’t like it when I find myself manipulating people **vs** I find it easy to manipulate people
Item 6: I usually get the respect that I deserve **vs** I insist upon getting the respect that is due me
Item 7: I try not to be a show off **vs** I am apt to show off if I get the chance
Item 8: Sometimes I am not sure of what I am doing **vs** I always know what I am doing
Item 9: Sometimes I tell good stories **vs** Everybody likes to hear my stories
Item 10: I like to do things for other people **vs** I expect a great deal from other people
Item 11: It makes me uncomfortable to be the center of attention **vs** I really like to be the center of attention
Item 12: Being an authority doesn’t mean that much to me **vs** People always seem to recognize my authority
Item 13: I hope I am going to be successful **vs** I am going to be a great person
Item 14: People sometimes believe what I tell them **vs** I can make anybody believe anything I want them to
Item 15: There is a lot that I can learn from other people **vs** I am more capable than other people
Item 16: I am much like everybody else **vs** I am an extraordinary person
###Output Format:
Please return your choices as a JSON-style dictionary, using the format below. Include the full statement selected.
Example:
```json
{
“1”: “When people compliment me, I sometimes get embarrassed”,
“2”: “I prefer to blend in with the crowd”,
…
}
Running the Study
For this experiment, I selected GPT-4.1 Mini as the language model—primarily because it’s cost-effective to operate 😅.
Each of the 15 character profiles (five strong, five mild, and five non-narcissistic) was evaluated as follows:
The relevant prompt, including the character profile, was submitted 100 times per character.
A temperature setting of 0.7 was used to introduce a degree of randomness and variability in responses, simulating more human-like inconsistency.
This approach generated a sizeable dataset for each character, capturing how an AI might variably interpret and express narcissistic traits across repeated trials.
from dotenv import load_dotenv
from fuzzywuzzy import fuzz
import json
import os
from openai import OpenAI
import pandas as pd
from time import sleep
import reif __name__ == "__main__":
# Setup OpenAI API ----------------
load_dotenv()
client = OpenAI(
api_key=os.environ.get("OPEN_AI_KEY"),
)
# Read AI Prompt ------------------
with open("data/npd_scale/ai_prompt.txt", "r") as file:
ai_prompt = file.read()
# Read Character Profiles ---------
character_profiles = pd.read_csv(
"data/npd_scale/character_profiles/npd_character_profiles.csv"
)
# Complete Scale ------------------
all_responses = [] # Collect responses here
for _, data in character_profiles.iterrows():
character_responses = []
# Update Prompt with Profile ------
character_name = data["Character Name"]
character_profile = data["Character Profile"]
character_ai_prompt = ai_prompt.replace(
"{{character_profile}}", character_profile)
for i in range(100):
sleep(2)
# Run Study -----------------------
response = client.chat.completions.create(
model="gpt-4.1-mini",
messages=[{"role": "user", "content": character_ai_prompt}],
temperature=0.7
)
response_content = response.choices[0].message.content
try:
match = re.search(r'json\s*(\{.*?\})\s*', response_content, re.DOTALL)
response_content = match.group(1)
response_content = json.loads(response_content)
except json.JSONDecodeError as e:
print(f"Error parsing {response_content}: {e}")
response_content = {} # Fallback to empty dict if parsing fails
response_dict = {
"character_name": character_name,
"study_iteration": i,
"character_responses": response_content
}
character_responses.append(response_dict)
all_responses.append(character_responses)
# Saving collected responses to a JSON file (example)
with open("data/npd_scale/character_responses/responses.json", "w") as f:
json.dump(all_responses, f, indent=4)
print("Study complete, responses saved.")16-Item Narcissistic Personality Inventory (NPI-16)
Responses were extracted from GPT's JSON outputs and scored according to the NPI-16 system. In cases where responses didn't precisely match the original statement pairs, fuzzy string matching was applied to map them to the correct questionnaire items.
if __name__ == "__main__":
# Scoring Key ---------------------
scoring_key = pd.read_csv(
"npd_scoring_table.csv")
# Read Scale Responses ------------
with open("character_responses/responses.json", "r") as f:
scale_responses = json.load(f)
scale_responses = pd.concat([
pd.DataFrame(i)
for i in scale_responses],
ignore_index=True)
scale_responses = pd.concat([
scale_responses.drop(columns="character_responses"),
scale_responses["character_responses"].apply(pd.Series)],
axis=1)
scale_responses = scale_responses.melt(
id_vars=["character_name", "study_iteration"],
var_name="item_number",
value_name="response")
# Fuzzy Match Response Options ----
scale_response_variations = scale_responses.loc[
:, ["response"]].drop_duplicates()
scoring_key_statements = scoring_key.loc[:, "Statement"]
def find_closest_statement(response: str) -> str:
best_ratio = 0
closest_statement = ""
for statement in scoring_key_statements:
current_ratio = fuzz.ratio(statement, response)
if current_ratio >= best_ratio:
best_ratio = current_ratio
closest_statement = statement
return closest_statement
scale_responses.loc[:, "closest_statement"] = scale_responses[
"response"].apply(find_closest_statement)
# Merge Scoring Key ---------------
scale_responses = (
scale_responses
.merge(
scoring_key,
how="inner",
left_on="closest_statement",
right_on="Statement")
)
# Summarise Responses -------------
scale_responses_summarised = (
scale_responses
.groupby(["character_name", "study_iteration"])
.agg(
npd_score=pd.NamedAgg("Score", "mean")
)
.reset_index()
)
Results (see Table 1) are summarised as means and standard deviations across the 100 runs per character. Higher scores reflect a stronger endorsement of narcissistic traits.
Cersei Lannister and Dennis Reynolds had the highest average scores, with low standard deviations—indicating strong, consistent endorsement of narcissistic items.
Lucille Bluth ranked third, endorsing about 50% of items on average. Her higher standard deviation, however, suggests more variation across runs.
Three other characters showed low, but non-zero, endorsement rates.
The remaining profiles did not endorse any narcissistic items across all runs.
scale_responses_summarised <-
py$scale_responses_summarised |>
as.data.table()
scale_responses_summary <-
scale_responses_summarised[, .(`Mean Score` = mean(npd_score),
`SD Score` = sd(npd_score)),
by = .(`Character Name` = character_name)]
setorder(scale_responses_summary, -`Mean Score`)
scale_responses_summary |>
flextable() |>
colformat_double(digits = 2) |>
autofit()Character Name | Mean Score | SD Score |
|---|---|---|
Cersei Lannister | 1.00 | 0.00 |
Dennis Reynolds | 0.75 | 0.04 |
Lucille Bluth | 0.48 | 0.11 |
Tom Haverford | 0.25 | 0.08 |
Barney Stinson | 0.19 | 0.02 |
Carrie Bradshaw | 0.11 | 0.04 |
Captain Raymond Holt | 0.00 | 0.02 |
Leslie Knope | 0.00 | 0.01 |
Chandler Bing | 0.00 | 0.01 |
Dr. Temperance Brennan | 0.00 | 0.01 |
Joe Goldberg | 0.00 | 0.01 |
Castiel | 0.00 | 0.00 |
Rachel Green | 0.00 | 0.00 |
Samwise Gamgee | 0.00 | 0.00 |
Tami Taylor | 0.00 | 0.00 |
A Notable Inconsistency
One issue quickly emerged: Joe Goldberg (a character easily recognised for narcissistic tendencies) had an average endorsement rate of 0. This does not reflect his well-established personality traits and suggests either a limitation in the profile's nuance, misalignment in response mapping, or potentially a blind spot in the AI's assessment process.
Hypersensitive Narcissism Scale (HNS)
The HNS was also employed in this study, as it is specifically designed to capture the covert aspects of narcissism—the subtle, hypersensitive nature and the tendency to adopt a perpetual victim mindset. This contrasts with the NPI, which primarily assesses the more overt, grandiose features of narcissism.
if __name__ == "__main__":
# Read Scale Responses ------------
with open("character_responses/hypersensitive_responses.json", "r") as f:
scale_responses = json.load(f)
scale_responses = pd.concat([
pd.DataFrame(i)
for i in scale_responses],
ignore_index=True)
scale_responses = pd.concat([
scale_responses.drop(columns="character_responses"),
scale_responses["character_responses"].apply(pd.Series)],
axis=1)
columns_to_expand = ["1", "2", "3", "4", "5", "6", "7", "8", "9", "10"]
expanded_df = scale_responses.copy()
for col in columns_to_expand:
expanded_cols = expanded_df[col].apply(pd.Series)
expanded_cols.columns = [f"{subcol}_{col}" for subcol in expanded_cols.columns]
expanded_df = expanded_df.drop(columns=col)
expanded_df = pd.concat([expanded_df, expanded_cols], axis=1)
scale_responses_long = pd.wide_to_long(
expanded_df,
stubnames=["item", "rating"],
i=["character_name", "study_iteration"],
j="item_number",
sep="_").reset_index()
# Summarise Responses -------------
scale_responses_long.loc[:, "rating"] = scale_responses_long["rating"].astype(int)
scale_responses_summarised = (
scale_responses_long
.groupby(["character_name", "study_iteration"])
.agg(total_score=pd.NamedAgg("rating", "sum"))
.reset_index()
)
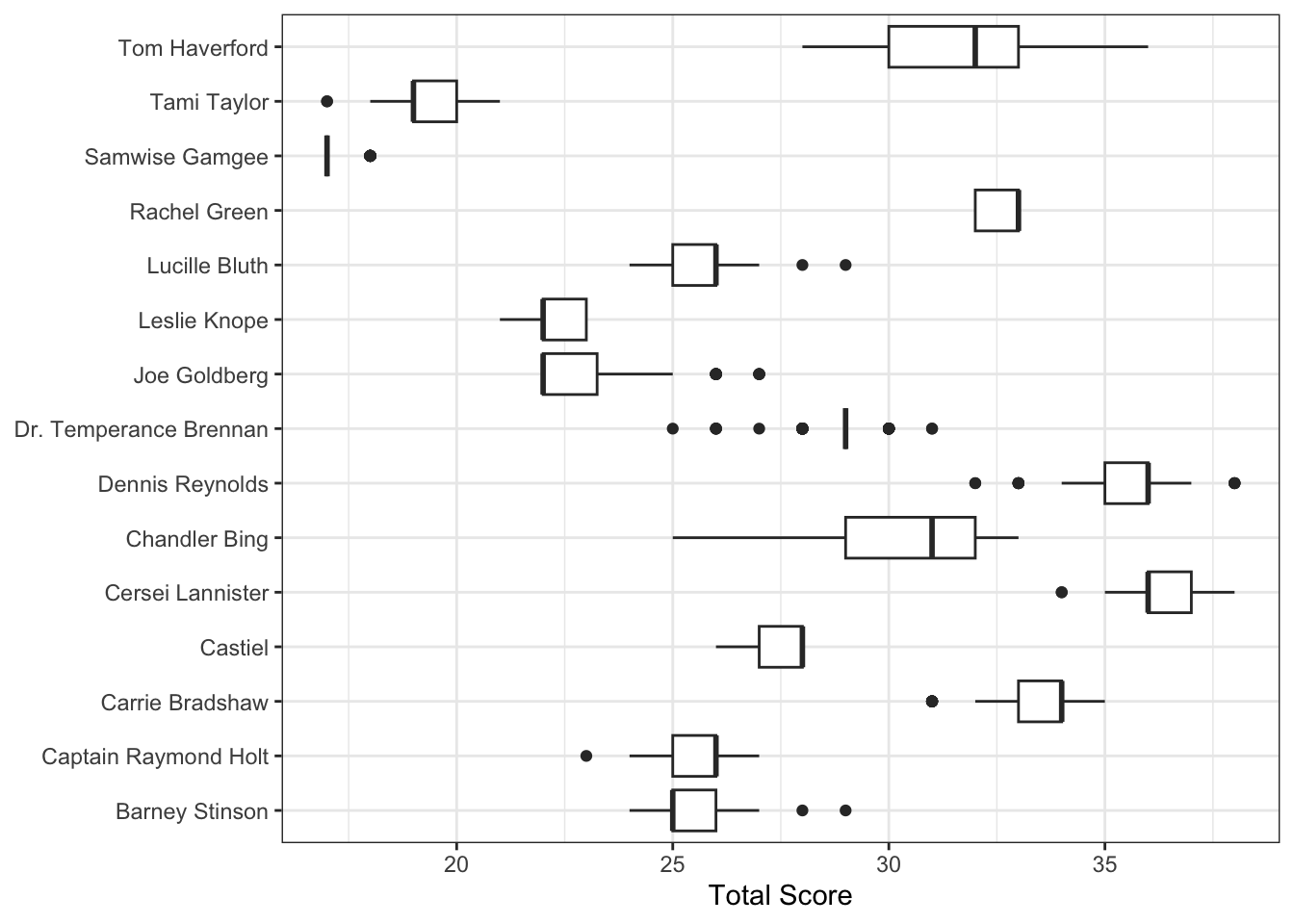
On the HNS, each character receives a total score based on the sum of their responses to 10 items (maximum possible score: 50). The distribution of scores across the 100 runs for each character is visualised in Figure 1 and summarised in Table 2.
Once again, Cersei Lannister and Dennis Reynolds achieved the highest average scores. Interestingly, the Dennis Reynolds profile exhibited more variability on the HNS than on the NPI, suggesting that the way hypersensitive narcissism is expressed in the character's profile may be more open to interpretation. Lucille Bluth ranked lower on the HNS compared to her NPI score, whereas Rachel Green and Carrie Bradshaw showed the opposite trend, scoring higher on the HNS.
Joe Goldberg remains a challenge: Similar to the NPI results, his profile received consistently low scores on the HNS, indicating few narcissistic traits. Given Joe's well-documented narcissistic behavior, this discrepancy suggests that the current character profile, or perhaps the AI's interpretation, fails to adequately capture or express his covert narcissism.
scale_responses_summarised <-
py$scale_responses_summarised |>
as.data.table()
scale_responses_summarised[, total_score := as.numeric(total_score)]
scale_responses_summarised |>
ggplot(aes(x = total_score, y = character_name)) +
geom_boxplot() +
theme_bw() +
labs(
x = "Total Score",
y = NULL
)
scale_responses_summary <-
scale_responses_summarised[, .(`Mean Score` = mean(total_score),
`SD Score` = sd(total_score)),
by = .(`Character Name` = character_name)]
setorder(scale_responses_summary, -`Mean Score`)
scale_responses_summary |>
flextable() |>
colformat_double(digits = 2) |>
autofit()Character Name | Mean Score | SD Score |
|---|---|---|
Cersei Lannister | 36.23 | 0.75 |
Dennis Reynolds | 35.58 | 1.33 |
Carrie Bradshaw | 33.23 | 1.02 |
Rachel Green | 32.63 | 0.49 |
Tom Haverford | 31.50 | 1.86 |
Chandler Bing | 30.42 | 2.35 |
Dr. Temperance Brennan | 28.81 | 0.95 |
Castiel | 27.52 | 0.69 |
Lucille Bluth | 25.70 | 1.00 |
Captain Raymond Holt | 25.52 | 0.89 |
Barney Stinson | 25.36 | 0.90 |
Joe Goldberg | 23.04 | 1.48 |
Leslie Knope | 22.24 | 0.49 |
Tami Taylor | 19.29 | 0.81 |
Samwise Gamgee | 17.21 | 0.41 |
Exploring the Character Profiles
To understand why Joe Goldberg is not being identified as displaying moderate to high narcissistic traits, it helps to examine his character profile and compare it directly with another, such as Dennis Reynolds:
Joe Goldberg Profile
I try to see people. Really see them—not just who they pretend to be. That can scare some folks. I’ve made choices others wouldn’t, but they don’t understand the full picture. When you care deeply about someone, you notice things others miss. You protect them, even when they don’t know they need protecting. People throw words like ‘obsession’ around too casually. I call it loyalty.
Dennis Reynolds Profile
I take pride in being composed, perceptive, and... let’s just say, unusually aware of how people work. I sometimes get accused of being manipulative, but I think people often confuse clarity with cruelty. I’ve developed systems—ways of interacting—that protect me and ensure I’m not wasting time on people who don’t meet my standards. Is that really so bad? It’s not like anyone ever handed me a roadmap for human connection.
At face value, the Joe Goldberg profile doesn't immediately shout "narcissism". Instead, it comes across as introspective, even somewhat self-effacing, with an emphasis on protecting others and caring deeply—even if misguidedly so. The language leans more toward themes of loyalty and misunderstood intent, rather than grandiosity or entitlement. Although a controlling undertone can be inferred.
Dennis Reynolds, on the other hand, explicitly uses language around pride, perceptiveness, and being misunderstood as manipulative. He refers to "systems" and "standards," which signal a more controlling, self-oriented worldview—traits closely associated with narcissism.
Why Subtlety May Hinder Detection
Joe's profile relies on subtext and rationalisation. While viewers of You recognise his narcissistic self-justification and lack of empathy, the AI may interpret his statements at face value, missing the undertones of self-absorption, control masked as care, or lack of guilt.
If a profile is too nuanced or indirect, the AI may fail to pick up on covert narcissism, especially if key narcissistic signals (grandiosity, explicit entitlement, exploitation of others) are downplayed or absent. In contrast, more overt language, as seen in Dennis's profile, tends to elicit a higher narcissism score from the AI.
Implications
A central limitation of using large language models for personality profiling is that LLMs interpret language at face value. They have little capacity for grasping subtext, sarcasm, or deeper character complexity—especially when these nuances are not made explicit in the given text. As a result, relying on AI to complete psychometric measures based on character profiles is inherently problematic. If a profile misses critical details or fails to capture a character's nuanced psychology, the resulting assessment will be misleading.
This underlines the necessity for carefully designed and iteratively refined profiles—analogous to the process of developing valid vignettes or questionnaire items in psychological research. Ideally, profiles should be reviewed not just by their creators, but also by domain experts. Such oversight can help ensure that key traits are neither understated nor omitted.
There’s also an important caveat when AI is tasked with assessing real people based on their self-descriptions, biographies, or other written materials. Individuals may—deliberately or not—embellish strengths, downplay flaws, or omit relevant information. This ability to withhold or distort information introduces substantial bias, further skewing any automated assessment.
Finally, it's crucial to reiterate: this method is not a scientific or clinical approach to personality assessment. The exercise is subject to multiple sources of bias and limitation. Tools like the NPI or HNS, when used in this context, are for exploration and entertainment only—they should never be relied upon for diagnostic or evaluative purposes.