# Libraries
library(data.table)
library(ggplot2)
library(kableExtra)
library(reticulate)
library(rvest)
library(scales)
library(SnowballC)
library(tidytext)
library(vader)
# Scrape the text data and transform to raw text
debate_transcript <-
read_html("https://www.presidency.ucsb.edu/documents/presidential-debate-philadelphia-pennsylvania") |>
html_elements(".field-docs-content") |>
html_text2()Overview
In this post, we’ll explore the 10 September 2024 Presidential Debate, focusing on the verbal approaches of Kamala Harris and Donald Trump. Through text mining and sentiment analysis, we aim to uncover key themes and emotional tones expressed during the event.
All data was sourced from the American Presidency Project. The raw transcript text was extracted and tokenised at a sentence level. Only texts associated with the speakers (Harris and Trump) were retained. By tokenising the debate transcript into sentences, we ensure that sentiment analysis is applied on a granular level, giving us more nuanced insights into the emotional tone of each speaker’s statements.
# Split data based on new line
debate_transcript <-
strsplit(debate_transcript, "\n") |>
as.data.table()
# Remove rows where the speaker value is blank
debate_transcript <-
debate_transcript[V1 != ""]
# Split the text into speaker and text columns (additional colon create 3 columns)
debate_transcript[, c("speaker", "text", "additional_text") := tstrsplit(V1, ":", fill = "")]
# Concatenate text with additional text (caused by additional colon placement)
debate_transcript[, text := paste0(text, additional_text)]
# Drop additional text column
debate_transcript[, c("additional_text", "V1") := NULL]
# Filter to debtate speakers
debate_transcript <-
debate_transcript[is.element(speaker, c("HARRIS", "TRUMP"))]# Token debate text into sentences
debate_transcript_sentences <-
debate_transcript |>
unnest_tokens("sentence", "text", token = "sentences")
# Split sentence data based on the speaker
debate_transcript_sentences <-
split(debate_transcript_sentences,
debate_transcript_sentences$speaker)Sentiment Analysis
VADER (Valence Aware Dictionary and sEntiment Reasoner) was used to calculate sentiment across the debate. VADER is mainly used for social media texts, but can be extended to other texts. It is a dictionary-based approach that calculates the level of positivity or negativity within a piece of text; scores range from -4 (negative sentiment) to 4 (positive sentiment).
In the context of a political debate, we would expect a mix of negative and neutral sentiment, especially during critiques or attacks. Positive sentiment could indicate persuasive or hopeful language aimed at connecting with the audience.
Relative Sentence Positions
We can compare the sentiment of each speaker across the debate. The problem is that Trump spoke a total of 795 sentences compared to Harris’s 336 sentences. This equates to 2.37 more sentences from Trump compared to Harris.
Using absolute positions for comparing sentiment changes over the debate is therefore not straightforward. To correct this we need to swap to the relative positions within the debate. This was achieved by adding the sentence number and converting this to a proportion. Sentences were segmented into 5% buckets. Average sentiment was then calculated within these buckets. This then allowed us to compare sentiment at different sections within each speakers transcript.
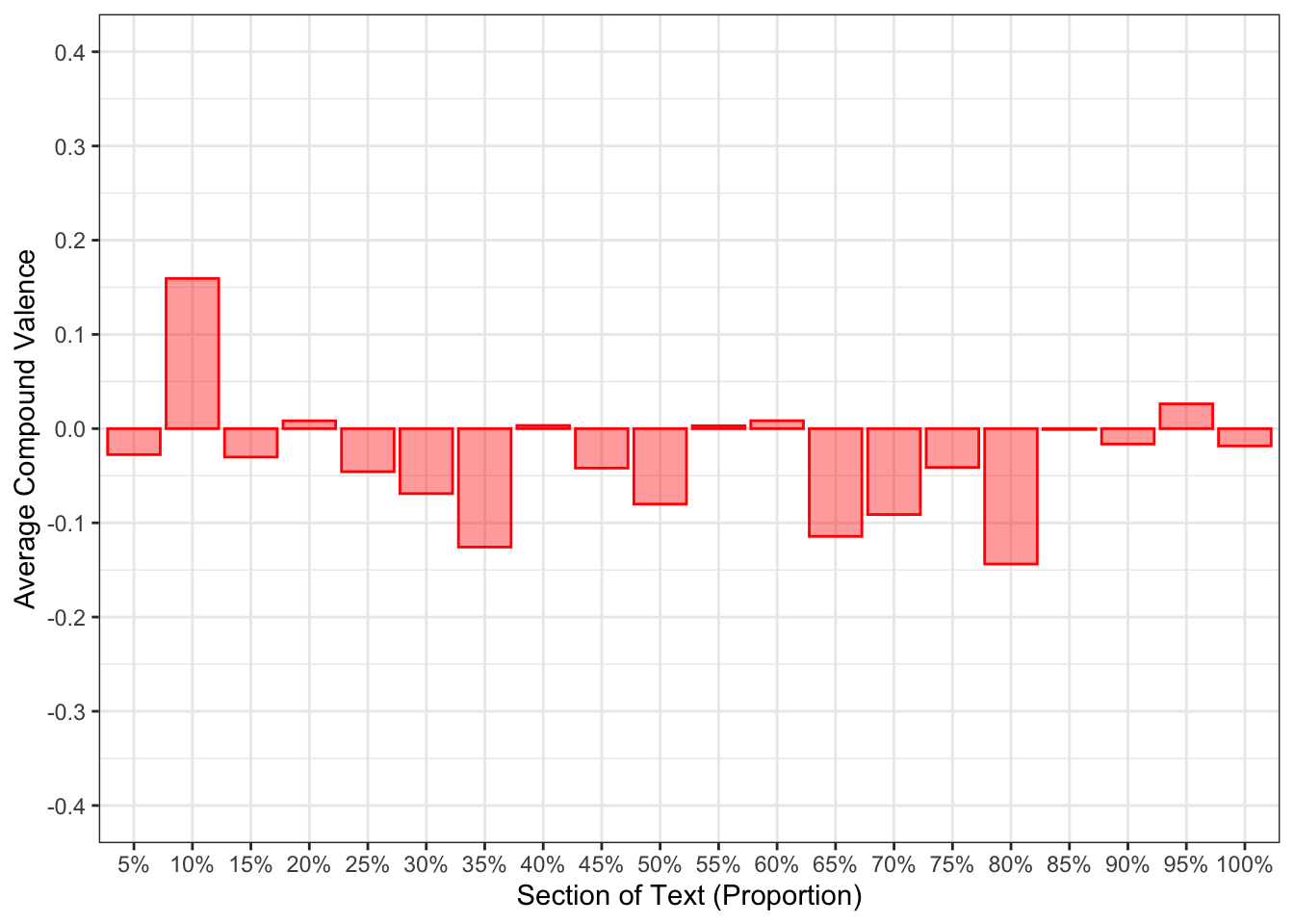
Figure 1 presents the sentiment changes for each speaker over the course of the debate (Harris, Figure 1 (a); Trump, Figure 1 (b)). Harris appeared to have a positive sentiment throughout most of their sections of the debate. At times, negative sentiment was expressed, but it did not characterise their transcript. Trump’s transcript expressed a high amount of negative sentiment throughout. Positive sentiment was expressed, but not at a level comparable to Harris’s.
debate_sentiment_bucket_plots <-
lapply(debate_transcript_sentences, function(x) {
# Assign colour based on speaker
colour <- ifelse(all(x$speaker == "HARRIS"), "blue", "red")
# Calculate sentiment at a sentence level and covert to data.table
x <- as.data.table(vader_df(x$sentence))
# Add index, proportion, and bucket columns
x[, index := 1:.N]
x[, proportion_in_text := index / .N]
x[, bucket_proportion := cut(proportion_in_text,
breaks = seq(0, 1, .05),
labels = paste0(seq(5, 100, 5), "%"))]
# Plot average sentiment by section of text
x[, .(avg_compound_valence = mean(compound)), by = bucket_proportion] |>
ggplot(aes(x = bucket_proportion, y = avg_compound_valence)) +
geom_col(
alpha = .4,
colour = colour,
fill = colour) +
scale_y_continuous(
breaks = seq(-.4, .4, .1),
limits = c(-.4, .4)
) +
theme_bw() +
labs(
x = "Section of Text (Proportion)",
y = "Average Compound Valence"
)
})
debate_sentiment_bucket_plots[[1]]
debate_sentiment_bucket_plots[[2]]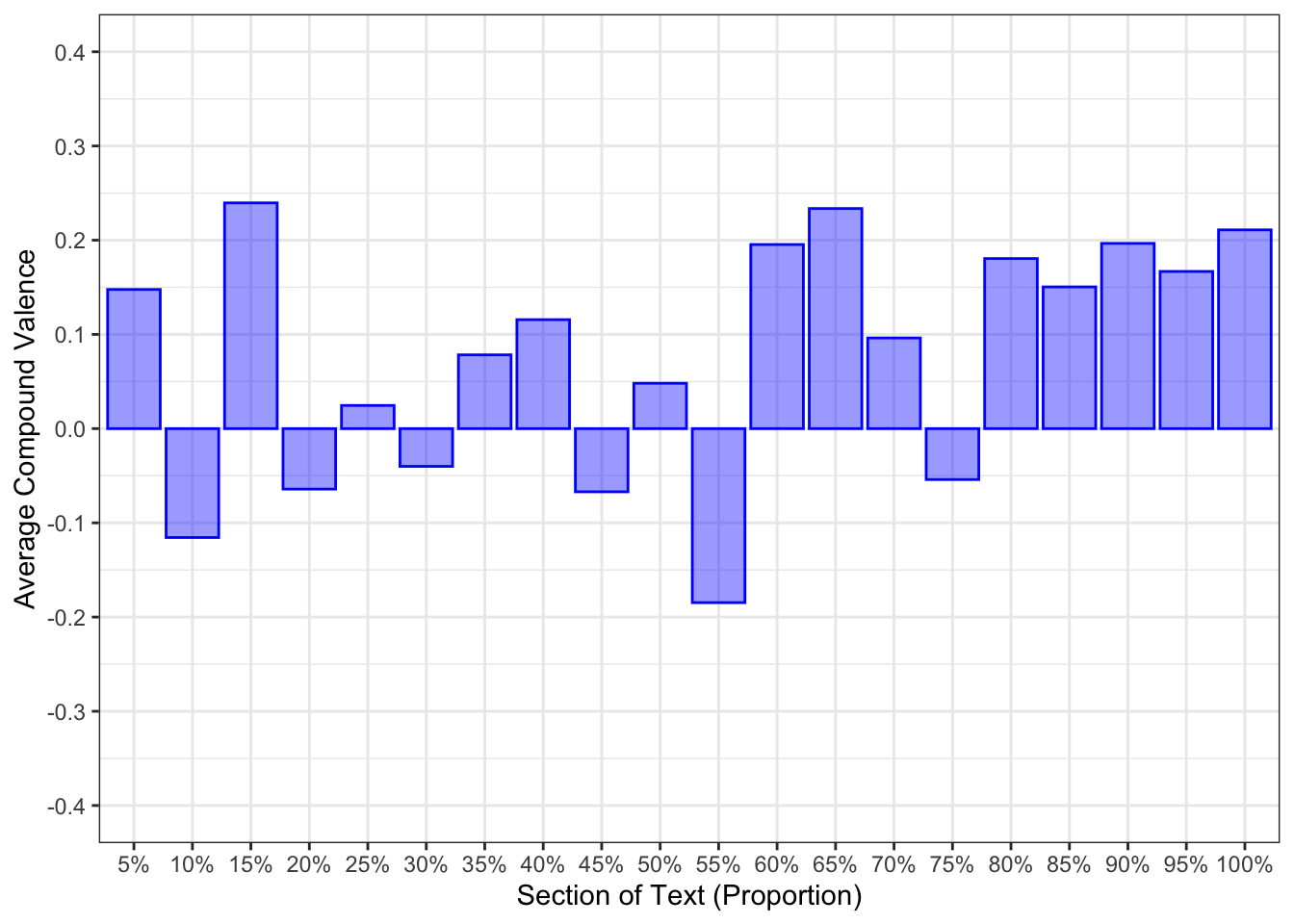
Rate of Change
We extend the sentiment analysis by exploring the rate of change. This represents how the speaker’s sentiment shifted at relative sections within the debate. While sentiment scores give us an overall picture of each speaker’s tone, analysing the rate of change allows us to track how quickly that tone shifts throughout the debate. This can reveal moments of emotional intensity or strategic pivots during their speeches.
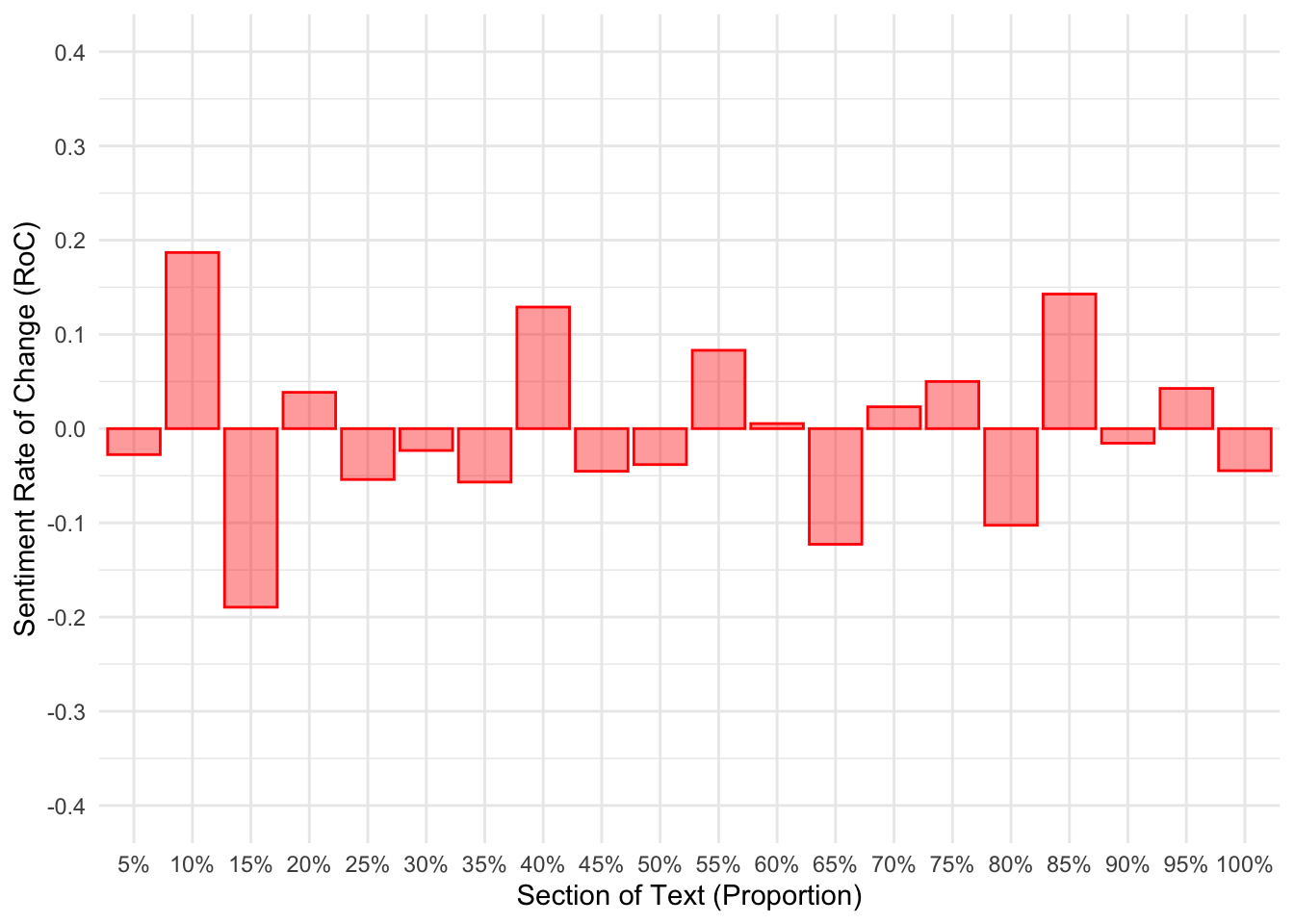
It was achieved by calculating the difference between the current and preceding sentiment scores. Figure 2 shows Harris’s sentiment to shift quite strongly in the first and third quarters of the debate (Figure 2 (a)). We know from Figure 1 (a) that these areas are when a high amount of positive sentiment was conveyed, shifting away from points of negative sentiment. Trump, on the other hand, does not show such changes in sentiment. We again know that Trump’s sentiment did not fluctuate over the course of the debate (Figure 1 (b)).
debate_sentiment_roc_plots <-
lapply(debate_transcript_sentences, function(x) {
# Assign colour based on speaker
colour <- ifelse(all(x$speaker == "HARRIS"), "blue", "red")
# Calculate sentiment at a sentence level and covert to data.table
x <- as.data.table(vader_df(x$sentence))
# Add index, proportion, and bucket columns
x[, index := 1:.N]
x[, proportion_in_text := index / .N]
x[, bucket_proportion := cut(proportion_in_text,
breaks = seq(0, 1, .05),
labels = paste0(seq(5, 100, 5), "%"))]
# Calculate average compound valence per bucket
x <-
x[, .(avg_compound_valence = mean(compound)), by = bucket_proportion]
# Calculate sentiment rate of change (RoC)
x[, sentiment_roc := avg_compound_valence - shift(avg_compound_valence,
n = 1,
type = "lag",
fill = 0)]
# Plot RoC
x |>
ggplot(aes(x = bucket_proportion, y = sentiment_roc, group = 1)) +
geom_col(
alpha = .4,
colour = colour,
fill = colour
) +
scale_y_continuous(breaks = seq(-.4, .4, .1),
limits = c(-.4, .4)) +
theme_minimal() +
labs(x = "Section of Text (Proportion)",
y = "Sentiment Rate of Change (RoC)")
})
debate_sentiment_roc_plots[[1]]
debate_sentiment_roc_plots[[2]]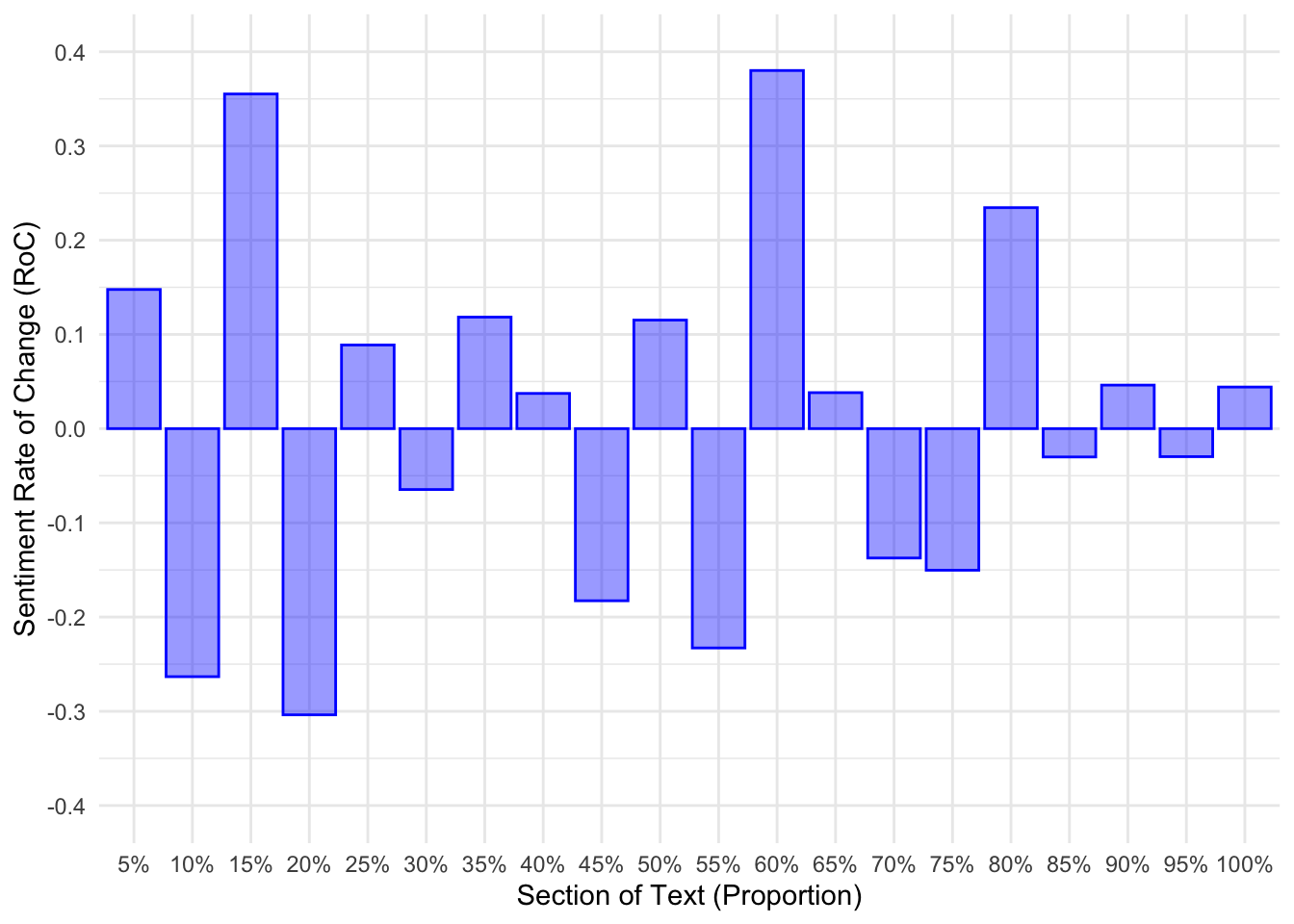
The rate of change provides us with a view of how emotions unfolded over the course of the debate. It is remains limited in providing details on what was spoken to contribute to these changes.
Exploring Sentiment Peaks and Valleys
To provide further insight beyond sentiment values, we can explore what sentence contributed to the largest positive and negative sentiment. This was achieved by identifying each speaker’s section of the debate that had either highest positive or negative sentiment score then filtering to the sentence contributing to this score.
Most Positive Sentence
Table 1 presents the most positive sentences. Harris appears to be referring how policy should be in the interest of the USA and securing its place as a global power. Trump’s sentence, on the other hand, is one of him being self-congratulatory.
most_positive_sentences <-
lapply(debate_transcript_sentences, function(x) {
speaker <- unique(x$speaker)
# Calculate sentiment at a sentence level and covert to data.table
x <- as.data.table(vader_df(x$sentence))
# Add index, proportion, and bucket columns
x[, index := 1:.N]
x[, proportion_in_text := index / .N]
x[, bucket_proportion := cut(proportion_in_text,
breaks = seq(0, 1, .05),
labels = paste0(seq(5, 100, 5), "%"))]
most_positive_bucket <-
x[,
.(avg_compound_valence = mean(compound)),
by = bucket_proportion][avg_compound_valence == max(avg_compound_valence),
bucket_proportion]
x <- x[bucket_proportion == most_positive_bucket]
x <- x[compound == max(compound), .(text)]
x[, speaker := speaker]
}) |>
rbindlist()most_positive_sentences[, .(speaker, text)] |>
kbl(col.names = c("Speaker", "Text")) |>
kable_paper()| Speaker | Text |
|---|---|
| HARRIS | basically sold us out, when a policy about china should be in making sure the united states of america wins the competition for the 21st century. |
| TRUMP | look, i went to the wharton school of finance and many of those professors, the top professors, think my plan is a brilliant plan, it's a great plan. |
Most Negative Sentences
Table 2 presents the most negative sentences. For Harris, this sentence is in relation to them discussing International Affairs. Whereas, Trump’s sentence is an attack directed towards their opponent.
most_negative_sentences <-
lapply(debate_transcript_sentences, function(x) {
speaker <- unique(x$speaker)
# Calculate sentiment at a sentence level and covert to data.table
x <- as.data.table(vader_df(x$sentence))
# Add index, proportion, and bucket columns
x[, index := 1:.N]
x[, proportion_in_text := index / .N]
x[, bucket_proportion := cut(proportion_in_text,
breaks = seq(0, 1, .05),
labels = paste0(seq(5, 100, 5), "%"))]
most_negative_bucket <-
x[,
.(avg_compound_valence = mean(compound)),
by = bucket_proportion][avg_compound_valence == min(avg_compound_valence),
bucket_proportion]
x <- x[bucket_proportion == most_negative_bucket]
x <- x[compound == min(compound), .(text)]
x[, speaker := speaker]
})most_negative_sentences[, .(speaker, text)] |>
kbl(col.names = c("Speaker", "Text")) |>
kable_paper()| Speaker | Text |
|---|---|
| HARRIS | women were horribly *****. |
| TRUMP | three days later he went in and he started the war because everything they said was weak and stupid. |
Debate Topics
Sentiment analysis has shown how clear differences in the tone of each speaker during the debate. We can extend this insight by exploring the topics raised within the debate. There’s a limited amount of text to perform a topic model. In-place, the sentence tokens were encoded into embeddings and clustered. A sample of 3 sentences per speaker and cluster (6 in total) are provided in Table 3.
import os
import pandas as pd
from sentence_transformers import SentenceTransformer
from sklearn.cluster import KMeans
os.environ["TOKENIZERS_PARALLELISM"] = "false"
debate_transcript_sentences = pd.concat(r.debate_transcript_sentences)
model = SentenceTransformer("all-MiniLM-L6-v2")
embeddings = model.encode(debate_transcript_sentences["sentence"])
k_means = KMeans(n_clusters=6, random_state=32).fit(embeddings)
cluster_labels = k_means.labels_The clusters can loosely be defined as follows:
Cluster 0: International Affairs, Military, and Leadership
Cluster 1: Domestic Issues and Socioeconomic Concerns
Cluster 2: Personal Narratives and Attacks
Cluster 3: Criticisms and Predictions
Cluster 4: Political Decision-Making
Cluster 5: Law Enforcement, Crime, and Social Justice
set.seed(100924)
debate_transcript_sentences <-
debate_transcript_sentences |>
rbindlist()
debate_transcript_sentences[, cluster := py$cluster_labels]
debate_transcript_sentences_sample <-
debate_transcript_sentences[, sample(sentence, size = 3), by = .(cluster, speaker)]
setorder(debate_transcript_sentences_sample, cluster)
debate_transcript_sentences_sample |>
kbl(col.names = c("Cluster", "Speaker", "Sentence")) |>
kable_paper()| Cluster | Speaker | Sentence |
|---|---|---|
| 0 | HARRIS | someone who has openly expressed disdain for members of our military. |
| 0 | HARRIS | the negotiation involved the taliban getting 5,000 terrorists, taliban terrorists, released. |
| 0 | HARRIS | and through the work that i and others did, we brought 50 countries together to support ukraine in its righteous defense. |
| 0 | TRUMP | they threw him out of a campaign like a dog. |
| 0 | TRUMP | putin would be sitting in moscow and he wouldn't have lost 300,000 men and women. |
| 0 | TRUMP | he said the most respected, most feared person is donald trump. |
| 1 | HARRIS | what is happening in our country, working people, working women who are working one or two jobs, who can barely afford childcare as it is, have to travel to another state--to get on a plane sitting next to strangers--to go and get the health care she needs. |
| 1 | HARRIS | the young people of america care deeply about this issue. |
| 1 | HARRIS | what we know is that this war must end. |
| 1 | TRUMP | it would totally destroy everything that they've set out to do. |
| 1 | TRUMP | the worst inflation we've ever had. |
| 1 | TRUMP | and now you have millions of people dead and it's only getting worse and it could lead to world war 3. |
| 2 | HARRIS | we call her our second mother. |
| 2 | HARRIS | kamala harris. |
| 2 | HARRIS | she was a small business owner. |
| 2 | TRUMP | and when she ran, she was the first one to leave because she failed. |
| 2 | TRUMP | she doesn't want to be called the border czar because she's embarrassed by the border. |
| 2 | TRUMP | that's up to her. |
| 3 | HARRIS | and i will tell you, the one thing you will not hear him talk about, is you. |
| 3 | HARRIS | and you know why? |
| 3 | HARRIS | look at his tweet. |
| 3 | TRUMP | and i've been pretty good at predictions. |
| 3 | TRUMP | in other words, we'll execute the baby. |
| 3 | TRUMP | and you know what? |
| 4 | HARRIS | you will see, during the course of his rallies he talks about fictional characters like hannibal lecter. |
| 4 | HARRIS | and it is absolutely well known that these dictators and autocrats are rooting for you to be president again because they're so clear, they can manipulate you with flattery and favors. |
| 4 | HARRIS | answer the question, would you veto-- |
| 4 | TRUMP | and you saw that with the decision that came down just recently from the supreme court. |
| 4 | TRUMP | but it doesn't matter, because this issue has now been taken over by the states. |
| 4 | TRUMP | they wouldn't vote to change it. |
| 5 | HARRIS | so i'm the only person on this stage who has prosecuted transnational criminal organizations for the trafficking of guns, drugs, and human beings. |
| 5 | HARRIS | i'll tell you, i started my career as a prosecutor. |
| 5 | HARRIS | he was a, a, a—land, he owned land, he owned buildings, and he was investigated because he refused to rent property to black families. |
| 5 | TRUMP | they allowed criminals. |
| 5 | TRUMP | they immediately let these guys go to where they were. |
| 5 | TRUMP | and how unfair that would have been-- part of the reason they lost--to the millions and millions of people that hadda pay off their student loans. |
Summary
In sum, our sentiment analysis shows clear differences between Harris and Trump during the 2024 Presidential Debate. While Harris maintained a more positive tone, Trump’s sentiment leaned negative throughout. These patterns, along with the rate of change in sentiment, highlight distinct strategies by both candidates to engage the audience. This was extended by identifying topics within the debate, which covered a range of areas: International Affairs, Personal Narratives, and Social Justice. Further analysis could compare how these sentiment trends align with audience reactions or media coverage. In-place of VADER, the NRC lexicon could be used to explore emotions such as anger, fear, and surprise.