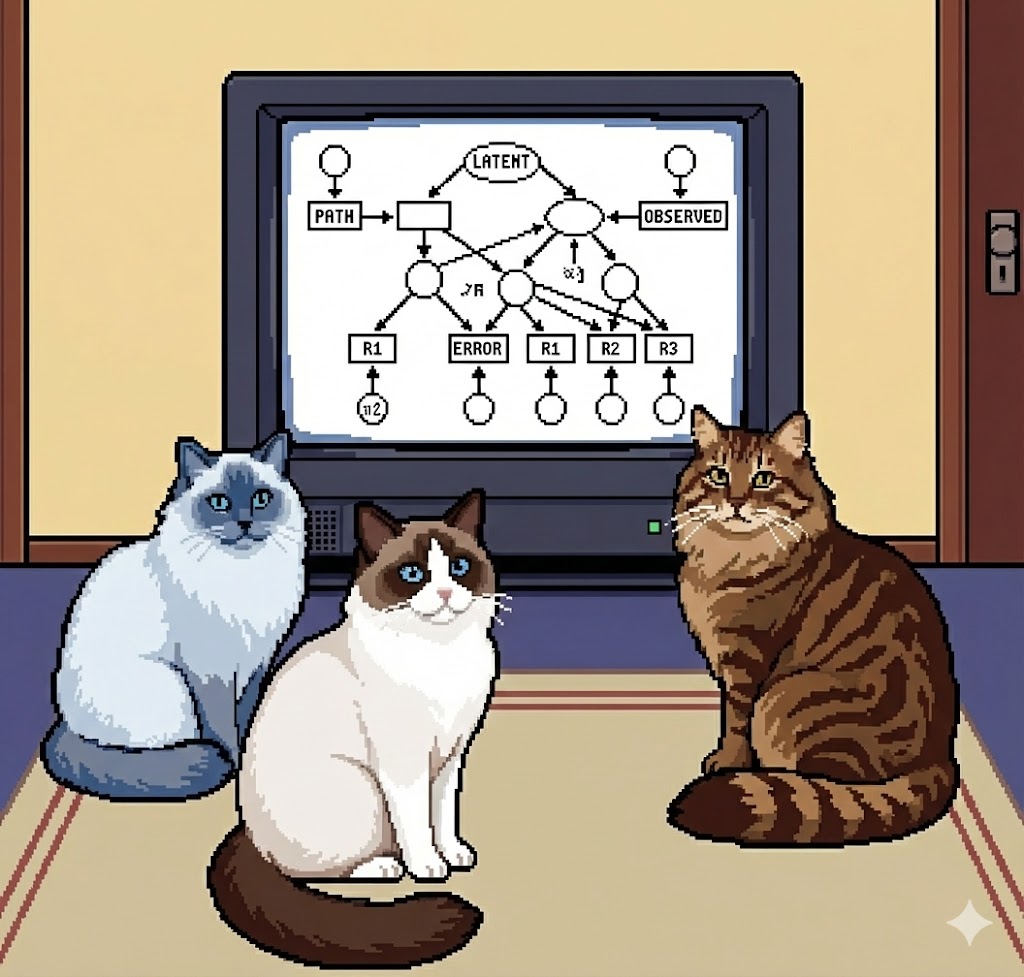
When Perfect Fit Isn’t Perfect: Rethinking a Trace-Data SEM
This post critically examines a published path analysis linking trace data to self-regulated learning processes. It highlights issues in the model’s specification and parameterisation, and discusses the implications of these problems for interpreting trace-based measures.
Equating Noise: Re-Examining a GPCM Study Through Simulation
This post critically reviews a GPCM-based equating study and uses simulation to assess the stability of its reported parameters. The findings show substantial uncertainty and highlight methodological oversights that undermine the study’s conclusions.
CAT Isn’t Magic: Why Item Bank Targeting Matters More Than the Algorithm
Even the best selection strategy fails when the bank is skewed. This simulation compares linear, random, and 54321 adaptive forms to show where each succeeds, where they break down, and why content coverage drives measurement quality.
Prompt Engineering and Reliability in AI Scoring of Candidate Essays
This post explores how prompt design and model parameters affect AI-based scoring of candidate essays. Using a simulation study, we test different prompt types, essay strengths, and temperature settings to evaluate consistency, discrimination, and reliability. By the end, you’ll understand the practical trade-offs of using LLMs in recruitment scoring and why human oversight remains essential.
When Measurement Models Break Down: Revisiting Remote Work and Job Satisfaction Research
This post re-examines a remote work study using structural equation modeling and finds that while remote work doesn’t affect job satisfaction, the original survey items measuring ‘job satisfaction’ and ‘teamwork’ actually overlap so much they can’t be distinguished statistically.
Fixing What’s Broken: Refining a Social Media Use Scale Through Rigorous Analysis
Even published measurement scales sometimes need improvement, as this psychometric analysis of a social media use scale clearly demonstrates. What started as a 31-item, four-factor instrument became a more defensible 23-item, three-factor scale through systematic evaluation of item performance and model fit.
When Small Samples Undermine Measurement: Lessons from Simulating the Overall Disability Scale
What happens when robust psychometric tools are used on small samples? Through repeated simulations with the Overall Disability Scale for POEMs, we reveal how even well-designed measures can yield unreliable scores, and what this means for clinicians and researchers relying on patient-reported outcomes.

Can GPT Play a Narcissist? Testing Psychometric Consistency Across Fictional Profiles
Testing whether a GPT model consistently interpret narcissistic traits in fictional character profiles across repeated psychometric assessments, revealing limitations in AI’s ability to detect subtle psychological characteristics.

Practical Item Analysis: Understanding Easiness and Discrimination in Cognitive Assessments
This post provides a hands-on guide to performing item analysis on cognitive assessment items using Python. Learn how to simulate responses, evaluate item easiness, and calculate discrimination indices. By the end, you’ll be able to assess the quality of your items without relying on complex IRT models, making this approach useful for both item construction and the evaluation of existing item banks. Perfect for practitioners looking to enhance the effectiveness of recruitment assessments or other cognitive tests.
Sentiment Shifts and Topic Clusters: Dissecting the 2024 Presidential Debate
Using sentiment analysis and embeddings to explore the 2024 Presidential Debate.
Can We Predict Employee Happiness? Exploring Work Enjoyment with Random Forests
Using a combination of psychometric data and machine learning, we attempt to predict employee happiness.

Simulating the Effects of Item Drift on CATs
This simulation investigates the impact of item drift on computerised adaptive testing. It demonstrates how item compromise can lead to biased ability estimates and overexposed items, affecting the precision and validity of CATs.


AI Gets a Tinfoil Hat: Testing Conspiracy Beliefs with a Sunny Twist
Using Generative AI to determine who’s the biggest conspiracy theorist in the gang.

Exploring New Article Posts: Part 1
A quick exploration of news articles I scraped.